
使用GPU进行骨骼动画更新及蒙皮
CPU单线程动画的实现
在本学期的计算机动画课程(CS560)中,我实践了骨骼动画的读取,更新及蒙皮。具体步骤如下:
1:使用开源的模型读取库Assimp加载骨骼模型, 在读取完网格物体后,对于每个模型,收集对其有影响的骨骼,记录骨骼的默认矩阵及offset矩阵(offset矩阵是将顶点从模型空间转换到骨骼空间下的矩阵,当模型顶点乘以该矩阵后,得到的位置为相对于骨骼的位置), 并重新组织骨骼对顶点的影响权重(保留前几个数据,在本次项目中为4个)。然后对于每个动画,遍历动画树以确认是否有骨骼为模型骨骼的祖先节点但不影响模型。将以上骨骼数据同样记录下来。
2:对于每个动画,记录动画中所有骨骼的关键帧,由于位移,旋转和缩放的关键帧数不一定相同。
3:更新动画时, 遍历每个骨骼的关键帧序列,找到位于当前时间前后的两帧, 然后对该两帧数据进行插值计算得到当前时间下该骨骼的本地变换矩阵(对于位移及缩放进行线性插值(Lerp),对旋转进行球面插值(SLerp)), 若该骨骼没有关键帧,则使用默认变换矩阵。然后,从根部遍历骨骼树,将子骨骼乘上父骨骼的变换矩阵,从而得到每个骨骼在模型空间下的变换矩阵。
4:对于蒙皮部分,需要将骨骼对顶点的影响数据传入顶点着色器中,影响数据的内容包括影响每个顶点的骨骼id以及权重值。在本次项目中,由于每个顶点的骨骼数据被限制到了4个,故可以用逐顶点数据(attribute)的形式传入为一个vec4和一个ivec4,不过为了未来的可拓展性,我将其组织成了SSBO传入,并在着色器中通过gl_VertexIndex读取。除了骨骼顶点的影响数据,还需要传入骨骼本身的变换矩阵及offset矩阵(如果不需要绘制骨骼的debug线的话,offset矩阵可以在更新动画时预先乘到骨骼动画矩阵中)。最后在顶点着色器中,将顶点坐标和发现分别乘上4个骨骼的变换矩阵,再将4个结果加权相加,便可以得到模型空间下最终的顶点位置,下面的步骤和静态模型一样。
由于考虑到场景中可能会同时渲染多个模型,每个模型可能会做着不同的动画(或同一动画的不同帧),为了满足动画的实例化功能,我为每套动画申请了一个巨大的SSBO,并将该动画的所有实例数据存储在里面。每个动画实例都会将自己的数据更新到SSBO的一个分段里。
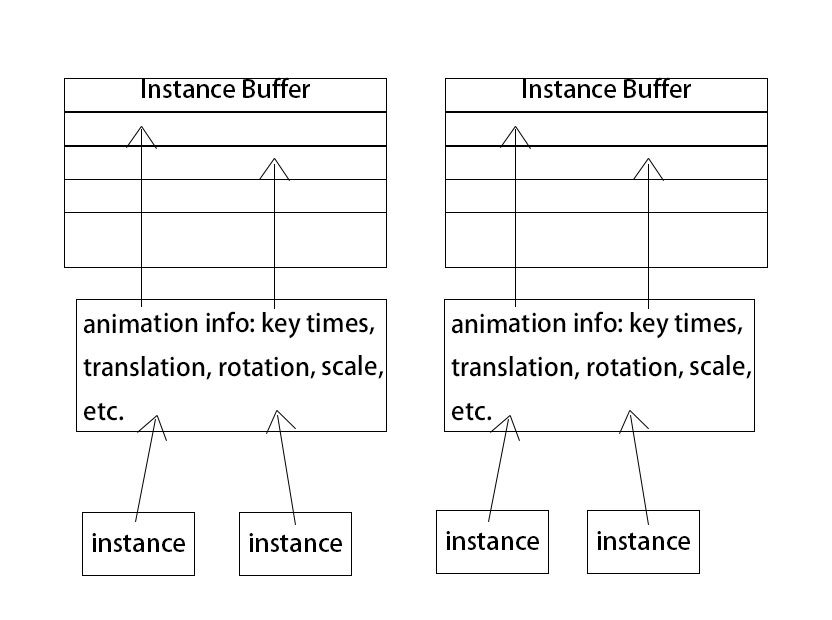
骨骼动画更新示意图
CPU骨骼动画
通过以上方法实现的动画有着不错的效果,不过由于是单线程执行,当动画实例的数量增加时,帧率会有明显的下降。为了明显提升动画的更新效率,使其能够大量运用于本学期的游戏项目中,我开始寻求在GPU上并行计算骨骼动画的方式。
重新组织关键帧数据
若想在GPU上更新动画,Compute shader大概是不二的选择,然而我并不能简单地将CPU上的逻辑直接写道shader里,毕竟glsl里没法存链表形式的骨骼树。因此,我对动画树进行了广度优先遍历,将所有的动画节点线性地存入一个数组中,同时再加上树每一层节点数的数组,做成两个SSBO。这样我只需线性地读取数组中地内容便可以更新动画矩阵了。除了节点数据,之外,每个节点地关键帧数据均以vec4数组地形式存储,并以std140格式传入,关键帧的时间单独以float数组形式存储,以std430格式传入。
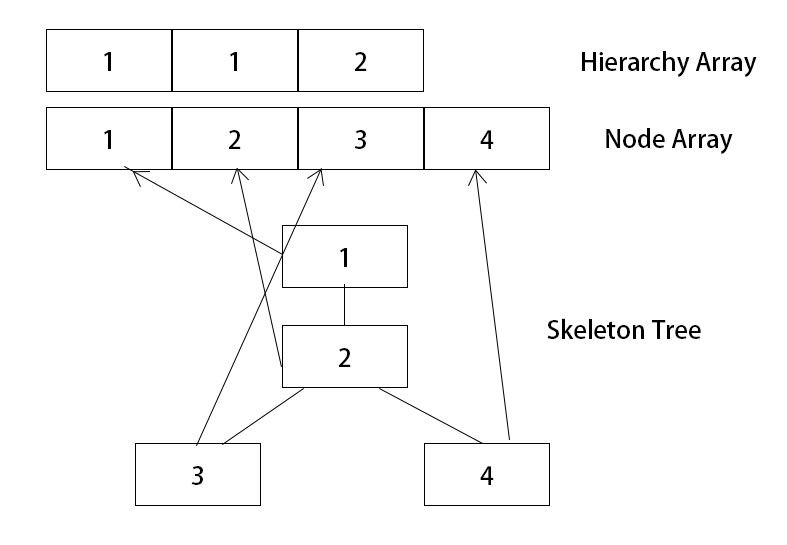
Compute Shader计算步骤
为了实现高效的并行化,我将节点矩阵的计算分为以下几步:
1:每个线程并行计算节点的本地变换矩阵,将结果存在共享矩阵数组中,由于本地变换矩阵不涉及父子关系,故可以完全并行地完成。计算完成后进行barrier同步。
2:按顺序并行计算动画树每一层节点地模型空间变换矩阵,没计算完一层进行一次barrier同步,由于位于同一层中的节点没有依赖关系,故同样可以并行地完成计算。计算结果覆盖步骤1中地数据。
3:将共享数组中地矩阵并行地拷贝到该实例的输出SSBO中。
计算完成后地蒙皮步骤与CPU更新时没有什么区别,这样,我便成功地实现了在GPU上更新动画的功能。
Bug及需要改进的地方
在实现GPU动画后的测试中,我发现了一个bug,该算法在同学的电脑上(GTX 970 Ti)运行时无法正确地播放动画,通过RenderDoc调试后发现计算出来的矩阵值变为了NaN。事后发现这个bug似乎时驱动造成的。不过为了保证代码的通用性,我还是做了进一步调试,发现问题可能是在关键帧插值时delta值出现了-0现象,在将delta进行了clamp处理后在旧的驱动下问题也消失了。除了以上这个bug,我认为这个算法还有可以优化的地方,比如在查找插值关键帧时,我使用了线性查找。之后我会尝试将其换为二分法查找。